前言
Google 出的 Guava 是 Java 核心增强的库,应用非常广泛。
我平时用的也挺频繁,这次就借助日常使用的 Cache 组件来看看 Google 大牛们是如何设计的。
缓存
本次主要讨论缓存。
缓存在日常开发中举足轻重,如果你的应用对某类数据有着较高的读取频次,并且改动较小时那就非常适合利用缓存来提高性能。
缓存之所以可以提高性能是因为它的读取效率很高,就像是 CPU 的 L1、L2、L3 缓存一样,级别越高相应的读取速度也会越快。
但也不是什么好处都占,读取速度快了但是它的内存更小资源更宝贵,所以我们应当缓存真正需要的数据。
其实也就是典型的空间换时间。
下面谈谈 Java 中所用到的缓存。
JVM 缓存
首先是 JVM 缓存,也可以认为是堆缓存。
其实就是创建一些全局变量,如 Map、List 之类的容器用于存放数据。
这样的优势是使用简单但是也有以下问题:
- 只能显式的写入,清除数据。
- 不能按照一定的规则淘汰数据,如
LRU,LFU,FIFO等。 - 清除数据时的回调通知。
- 其他一些定制功能等。
Ehcache、Guava Cache
所以出现了一些专门用作 JVM 缓存的开源工具出现了,如本文提到的 Guava Cache。
它具有上文 JVM 缓存不具有的功能,如自动清除数据、多种清除算法、清除回调等。
但也正因为有了这些功能,这样的缓存必然会多出许多东西需要额外维护,自然也就增加了系统的消耗。
分布式缓存
刚才提到的两种缓存其实都是堆内缓存,只能在单个节点中使用,这样在分布式场景下就招架不住了。
于是也有了一些缓存中间件,如 Redis、Memcached,在分布式环境下可以共享内存。
具体不在本次的讨论范围。
Guava Cache 示例
之所以想到 Guava 的 Cache,也是最近在做一个需求,大体如下:
从 Kafka 实时读取出应用系统的日志信息,该日志信息包含了应用的健康状况。
如果在时间窗口 N 内发生了 X 次异常信息,相应的我就需要作出反馈(报警、记录日志等)。
对此 Guava 的 Cache 就非常适合,我利用了它的 N 个时间内不写入数据时缓存就清空的特点,在每次读取数据时判断异常信息是否大于 X 即可。
伪代码如下:
|
1 |
@Value(“${alert.in.time:2}”) @Bean /** //将缓存清空 |
|---|
首先是构建了 LoadingCache 对象,在 N 分钟内不写入数据时就回收缓存(当通过 Key 获取不到缓存时,默认返回 0)。
然后在每次消费时候调用 checkAlert() 方法进行校验,这样就可以达到上文的需求。
我们来设想下 Guava 它是如何实现过期自动清除数据,并且是可以按照 LRU 这样的方式清除的。
大胆假设下:
内部通过一个队列来维护缓存的顺序,每次访问过的数据移动到队列头部,并且额外开启一个线程来判断数据是否过期,过期就删掉。有点类似于我之前写过的 动手实现一个 LRU cache
胡适说过:大胆假设小心论证
下面来看看 Guava 到底是怎么实现。
原理分析
看原理最好不过是跟代码一步步走了:
示例代码在这里:
https://github.com/crossoverJie/Java-Interview/blob/master/src/main/java/com/crossoverjie/guava/CacheLoaderTest.java
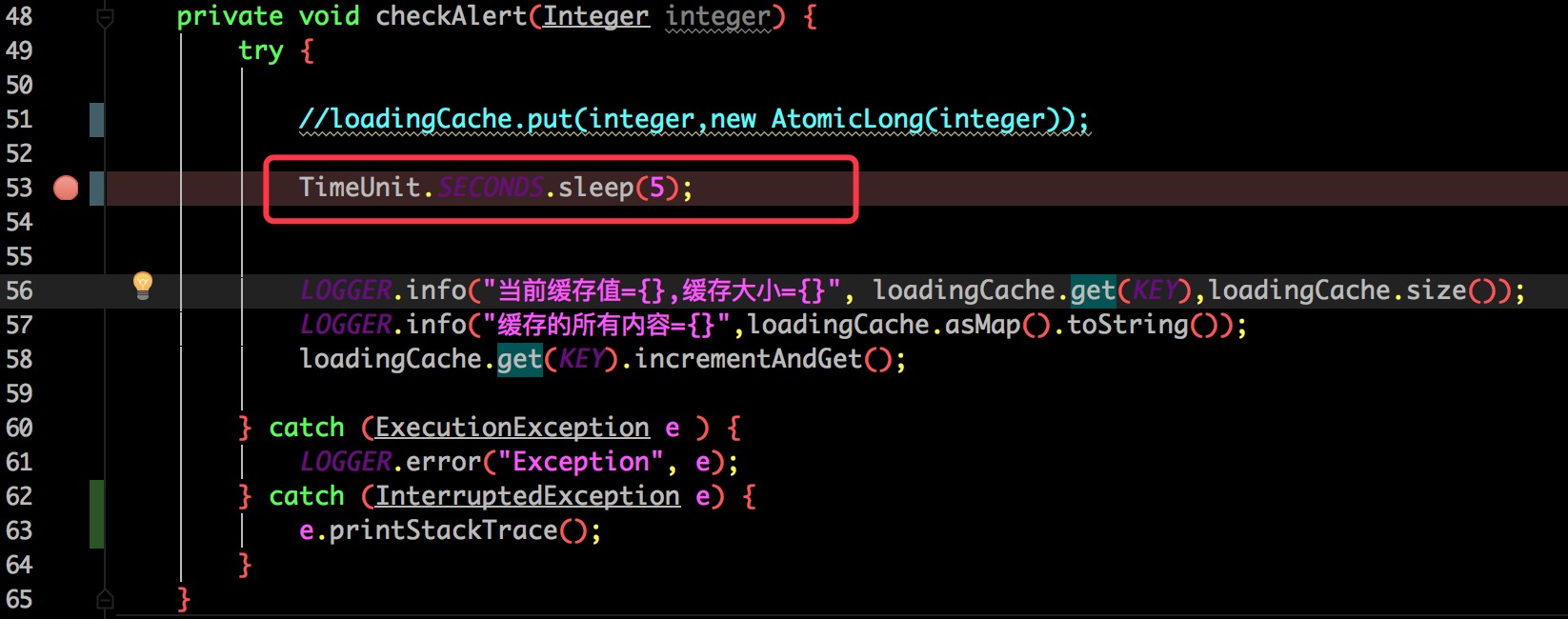
为了能看出 Guava 是怎么删除过期数据的在获取缓存之前休眠了 5 秒钟,达到了超时条件。
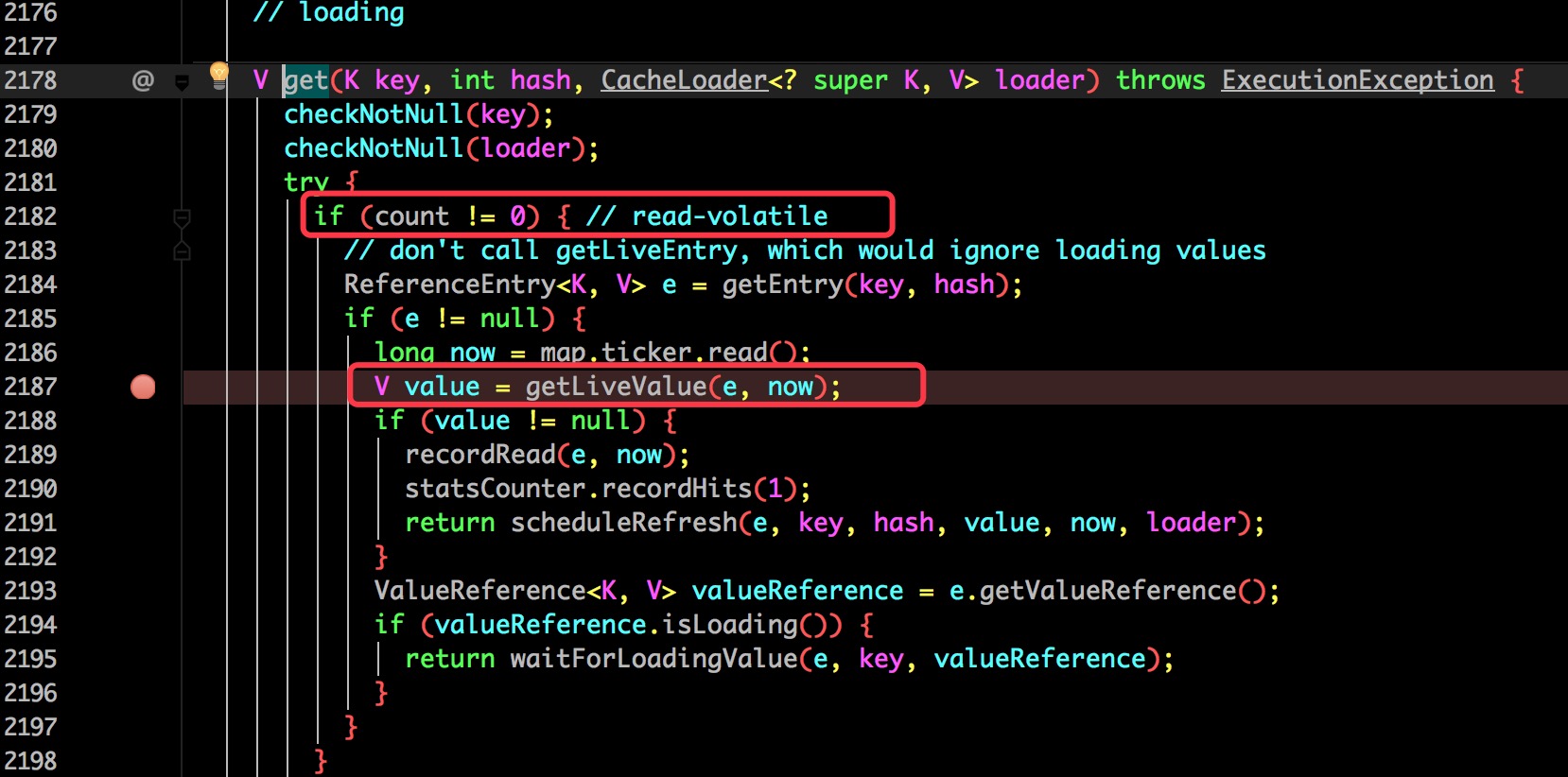
最终会发现在 com.google.common.cache.LocalCache 类的 2187 行比较关键。
再跟进去之前第 2182 行会发现先要判断 count 是否大于 0,这个 count 保存的是当前缓存的数量,并用 volatile 修饰保证了可见性。
更多关于 volatile 的相关信息可以查看 你应该知道的 volatile 关键字
接着往下跟到:

2761 行,根据方法名称可以看出是判断当前的 Entry 是否过期,该 entry 就是通过 key 查询到的。

这里就很明显的看出是根据根据构建时指定的过期方式来判断当前 key 是否过期了。
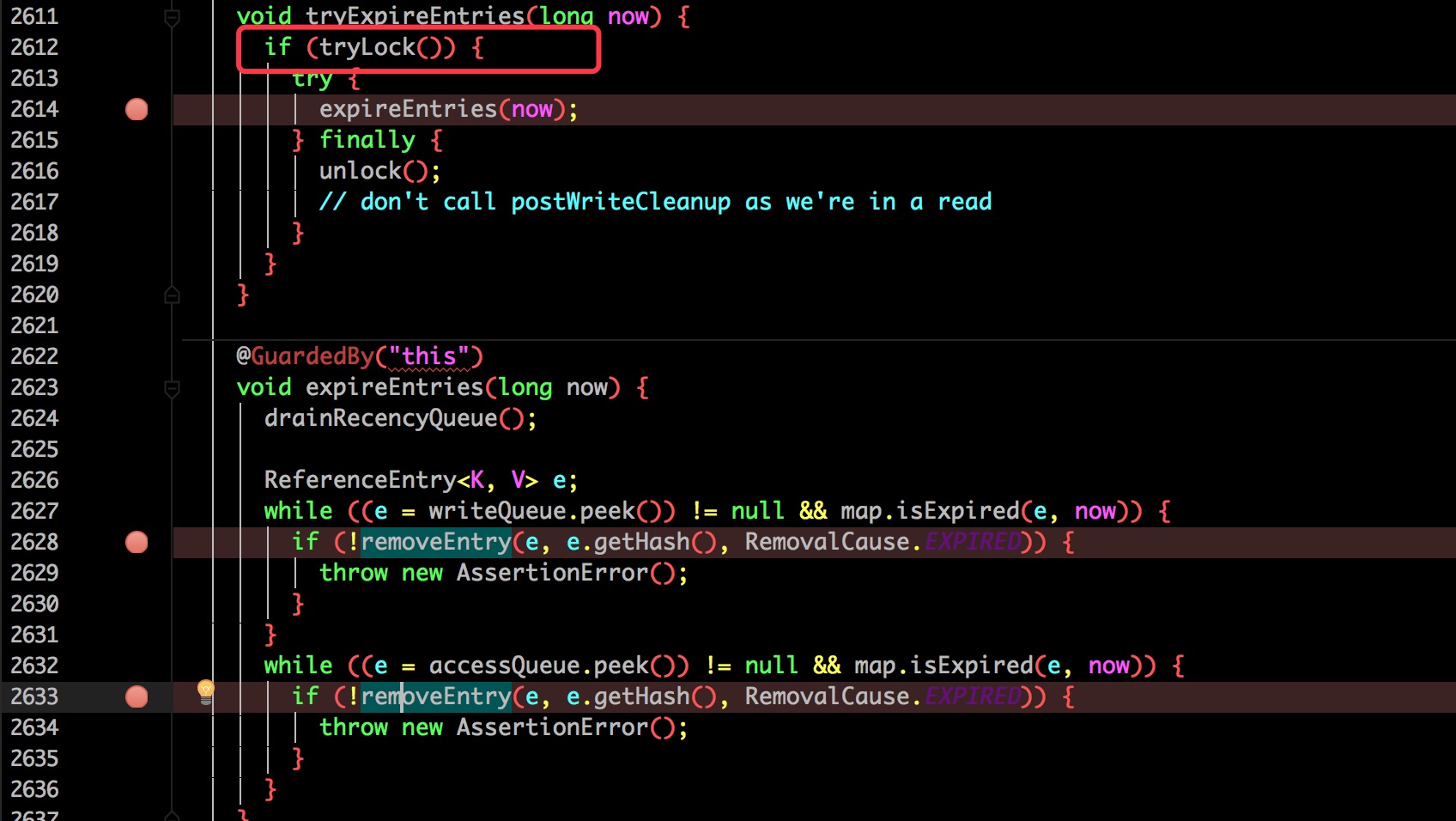
如果过期就往下走,尝试进行过期删除(需要加锁,后面会具体讨论)。
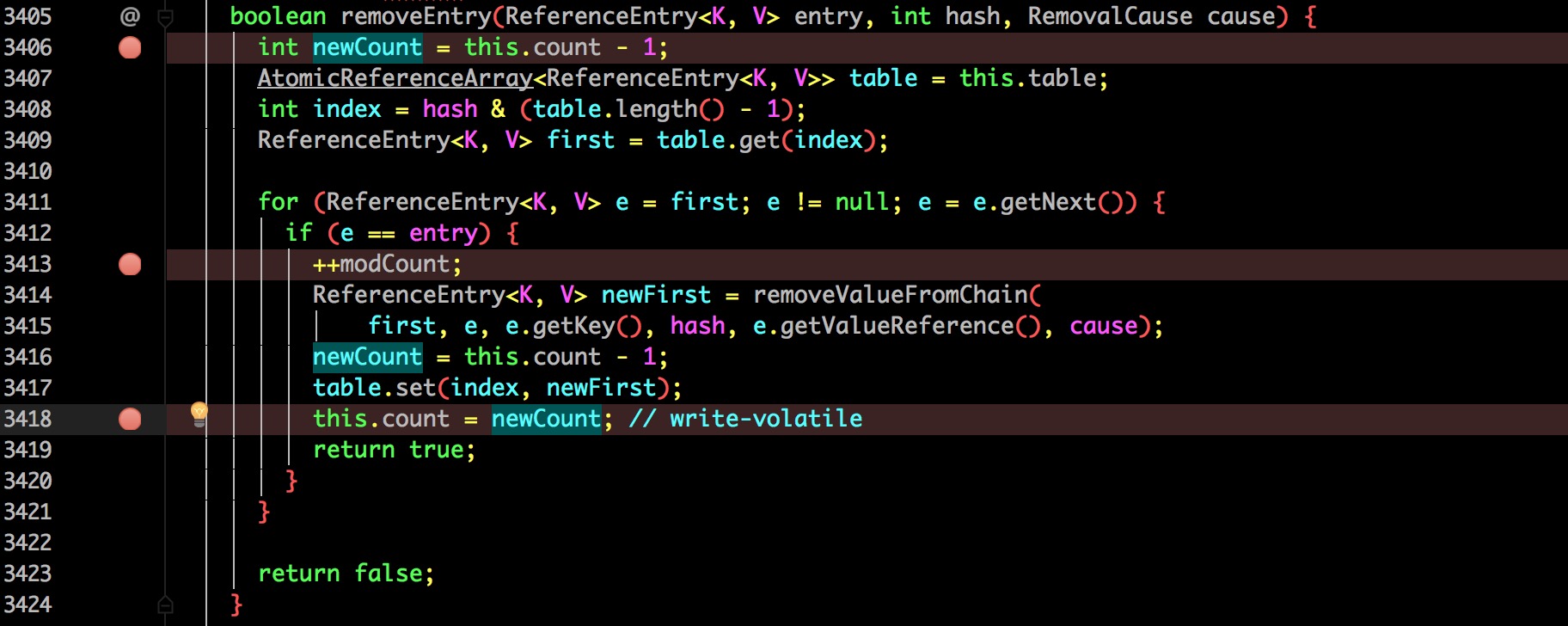
到了这里也很清晰了:
- 获取当前缓存的总数量
- 自减一(前面获取了锁,所以线程安全)
- 删除并将更新的总数赋值到 count。
其实大体上就是这个流程,Guava 并没有按照之前猜想的另起一个线程来维护过期数据。
应该是以下原因:
- 新起线程需要资源消耗。
- 维护过期数据还要获取额外的锁,增加了消耗。
而在查询时候顺带做了这些事情,但是如果该缓存迟迟没有访问也会存在数据不能被回收的情况,不过这对于一个高吞吐的应用来说也不是问题。
总结
最后再来总结下 Guava 的 Cache。
其实在上文跟代码时会发现通过一个 key 定位数据时有以下代码:

如果有看过 ConcurrentHashMap 的原理 应该会想到这其实非常类似。
其实 Guava Cache 为了满足并发场景的使用,核心的数据结构就是按照 ConcurrentHashMap 来的,这里也是一个 key 定位到一个具体位置的过程。
先找到 Segment,再找具体的位置,等于是做了两次 Hash 定位。
上文有一个假设是对的,它内部会维护两个队列 accessQueue,writeQueue 用于记录缓存顺序,这样才可以按照顺序淘汰数据(类似于利用 LinkedHashMap 来做 LRU 缓存)。
同时从上文的构建方式来看,它也是构建者模式来创建对象的。
因为作为一个给开发者使用的工具,需要有很多的自定义属性,利用构建则模式再合适不过了。
Guava 其实还有很多东西没谈到,比如它利用 GC 来回收内存,移除数据时的回调通知等。之后再接着讨论。
文章来源于互联网:Guava 源码分析(Cache 原理)
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.dandroid.cn/16849,转载请注明出处。



评论0