Java SPI原理与源码分析
概述
SPI是Service Provider Interface的缩写,jdk1.6版本开始内置的一种扩展机制,主要用于扩展框架的能力,其实就是框架定义一种能力(规范)和一些常规能力实现,在大部分业务场景下,基本满足需求,但是在一些定制化的场景框架默认的实现可能存在局限,那么我们就可以按照框架定义的规范自定义实现某种能力,然后在应用启动时把我们的自定义实现连同默认实现一同加载并实例化到容器中去,然后按照需要选择使用常规能力或者自定义能力,举个栗子,在Dubbo的负载均衡机制中,我们可以自己实现负载策略,然后消费服务的时候使用我们自己的策略。
与SPI比较类似的一个概念叫做API(Application Programming Interface),两者主要是语义和使用群体上存在不同:
- API:侧重于接口能力,使用群体是开发人员,比如前后端功能对接使用http接口,不用业务领域之间通过rpc接口等
- SPI:侧重于扩展能力,使用群体偏底层框架扩展人员,根据SPI规范扩展某种能力,供业务开发人员使用
对于API与SPI的区别我们可以用一张图更清晰的表现出来:
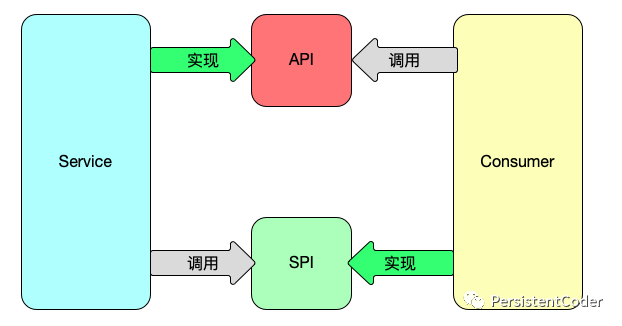
对于API,我们提供一种接口定义,服务端实现接口并提供服务,然后消费端通过接口定义找到服务实现并调用服务;对于SPI,同样可以理解为提供一种接口定义,由消费端提供能力实现,然后由服务端(可以理解为框架)来调用。
对于SPI的概念,简单来说就是一种动态替换发现的机制,可以在运行时添加实现,我们经常遇到的就是java.sql.Driver接口,其他不同厂商可以针对同一接口做出不同的实现,mysql和postgresql都有不同的实现提供给用户,而Java的SPI机制可以为某个接口寻找服务实现。
二
使用方式
java中提供SPI能力支持的核心类是ServiceLoader,从官方文档中我们可以看出,使用SPI大致需要三个步骤,分别是定义接口或者抽象类,甚至可以是一个具体的类(官方不建议使用)以及具体子类实现,在应用的resources路径新建/META-INF/services/目录,然后使用接口的全路径名定义一个文件,文件内容是接口的实现类,多个实现类换行,然后使用ServiceLoader加载接口实现并调用。
1:定义接口和实现
定义一个简单的接口:
public interface IHello {
/**
* sayHello
*/
void sayHello();
}定义两个实现:
public class ChineseHello implements IHello {
@Override
public void sayHello() {
System.out.println("你好");
}
}
public class EnglishHello implements IHello {
@Override
public void sayHello() {
System.out.println("hello");
}
}2:增加META-INF目录和文件
创建/META-INF/services目录,并且新建文件,文件名为接口全路径:
xxx.spi.IHello
文件内容是实现类全路径,如果有多个实现类,用换行隔开:
xxx.spi.ChineseHello
xxx.spi.EnglishHello3:加载并调用
调用方调用ServiceLoader加载接口实现并调用:
public static void main(String[] args) {
ServiceLoader serviceLoader = ServiceLoader.load(IHello.class);
Iterator iterator = serviceLoader.iterator();
while (iterator.hasNext()) {
IHello hello = iterator.next();
hello.sayHello();
}
}运行后可以看到执行结果:

我们定义的SPI接口已经被运行时加载并且能够被正常调用。
三
原理&源码分析
1:初始加载
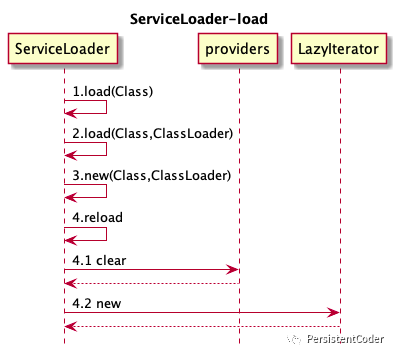
ServiceLoader类静态方法load会将接口定义以及类加载器初始化到内部类LazyIterator懒迭代器中。之所以叫做初始加载,是因为此时只是根据接口和类加载器定义一个懒迭代器,并不真正触发SPI文件的加载。
2:真实加载
在真正使用ServiceLoader加载的接口扩展实例之前,会先调用接口iterator方法,该方法只返回一个匿名迭代器实例(此时也不会加载):
public Iterator iterator() {
return new Iterator() {
Iterator> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}匿名迭代器定义了一个属性和三个方法实现:
- knownProviders属性:是一种缓存,每次加载和实例化的对象都会放入到本地缓存providers中(实现类全路径和实例化对象分别为key和value),此处获取本地缓存的迭代器赋值给knownProviders
- hasNext方法:先判断缓存迭代器是否还有元素,如果有直接返回true,否则调用ServiceLoader的懒迭代器的hasNext(第一次调用会触发真实加载)
- next方法:先判断缓存迭代器是否还有元素,如果有直接返回下一个元素,否则调用懒迭代器的next方法并返回结果
- remove:不支持移除操作,直接抛异常UnsupportedOperationException
在调用完ServiceLoader的iterator方法之后,会遍历元素(不管是for循环还是逐个迭代),由hasNext和next结合使用来实现:
while(hasNext()) {
next();
}先分析一下hasNext方法,前边有提到匿名迭代器的hasNext实现,第一次调用时本地缓存必定为空,会直接调用懒迭代器LazyIterator的hasNext方法:
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction action = new PrivilegedAction() {
public Boolean run() { return hasNextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}中间加载一些访问权限控制的逻辑,此处不必理会,该方法会调用内部的私有方法hasNextService:
private boolean hasNextService() {
//默认为空,当调用完hasNext再调用next方法就会有值,直接返回
if (nextName != null) {
return true;
}
if (configs == null) {
try {
//META-INF/services/xxx.interface
String fullName = PREFIX + service.getName();
// 加载文件
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
//遍历并解析文件内容
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}该方法是加载SPI接口实现文件的核心方法,首先构造出SPI文件全路径,然后加载文件,最后解析文件内容并返回,while执行条件是pending为空或者pending没有后续节点,如果解析出的文件路径没有更多元素(只有一个SPI文件)直接返回false,否则调用parse方法解析(将文件里边内容解析成实现类全路径迭代器),接着看parse方法实现:
private Iterator parse(Class> service, URL u)
throws ServiceConfigurationError
{
InputStream in = null;
BufferedReader r = null;
ArrayList names = new ArrayList<>();
try {
in = u.openStream();
r = new BufferedReader(new InputStreamReader(in, "utf-8"));
int lc = 1;
while ((lc = parseLine(service, u, r, lc, names)) >= 0);
} catch (IOException x) {
fail(service, "Error reading configuration file", x);
} finally {
try {
if (r != null) r.close();
if (in != null) in.close();
} catch (IOException y) {
fail(service, "Error closing configuration file", y);
}
}
return names.iterator();
}此处入参service就是接口定义,u是资源路径(META-INF/services/xxx.interface资源定位符),方法作用就是打开文件输入流,然后逐行读取并且把每一行的内容深度解析成实现类全路径添加到names列表中,继续看parseLine方法:
private int parseLine(Class> service, URL u, BufferedReader r, int lc,
List names)
throws IOException, ServiceConfigurationError
{
String ln = r.readLine();
if (ln == null) {
return -1;
}
int ci = ln.indexOf('#');
if (ci >= 0) ln = ln.substring(0, ci);
ln = ln.trim();
int n = ln.length();
if (n != 0) {
if ((ln.indexOf(' ') >= 0) || (ln.indexOf('t') >= 0))
fail(service, u, lc, "Illegal configuration-file syntax");
int cp = ln.codePointAt(0);
if (!Character.isJavaIdentifierStart(cp))
fail(service, u, lc, "Illegal provider-class name: " + ln);
for (int i = Character.charCount(cp); i < n; i += Character.charCount(cp)) {
cp = ln.codePointAt(i);
if (!Character.isJavaIdentifierPart(cp) && (cp != '.'))
fail(service, u, lc, "Illegal provider-class name: " + ln);
}
if (!providers.containsKey(ln) && !names.contains(ln))
names.add(ln);
}
return lc + 1;
}该方法的作用是读取行内容,然后剔除无用的注释和空白符,并检查是否是合法的java类命名,最后检查如果本地缓存不存在该类内容(防止内容覆盖)并且没有解析过该类,就把解析出来的实现类全路径放入列表中。
回到LazyIterator的hasNext方法,SPI文件解析之后将的下一个元素赋值给nextName(供next调用使用)并返回。ServiceLoader的匿名迭代器的hasNext方法调用时序图大致如下:
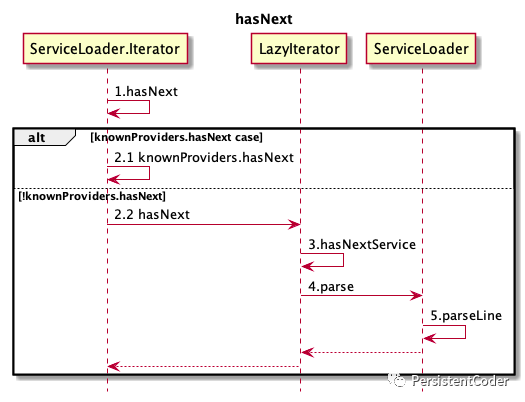
一般情况下调用完ServiceLoader迭代器的hasNext方法后会接着调用next方法,两者需要搭配使用,next方法实现基本思路和hasNext很相近,优先从缓存中检查有没有元素有的话直接返回缓存迭代器的元素中的value,否则调用LazyIterator的next方法获取实现类实例,接着看LazyIterator的next方法实现:
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}该方法的实现思路是先检查是否还有元素,没有的话直接报错,然后使用指定类加载器根据实现类全路径加载类,把全路径加载成Class类型,然后检查加载出的Class类是否派生于定义的接口,最后调用加载出的Class类的无参构造器生成实例并转换成接口类型,并放入缓存。
到这里java内置SPI实现方式以及核心类ServiceLoader的实现原理和源码都分析完了,总结一下其实整个流程下来干了以下几件事:
- 将传入接口定义成一个懒迭代器
- 检查是否有元素时加载并解析SPI文件
- 遍历迭代器时初始化子类实现并缓存
- 拿到实例化对象并提供调用
四
优缺点
java内置SPI的优点是解耦,使得接口的定义与具体业务实现分离,给开发人员提供了接口扩展能力,做一些定制化的实现,但是其缺点也特别明显:
- 无法按需加载
虽然使用了延迟加载,但是加载的时候还是需要全部遍历获取,需要将接口的实现类全部载入并实例化,如果不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,便造成了浪费。
- 获取特定实现类不灵活
只能通过迭代器遍历的方式获取,无法通过特定参数(比如实现类名称)类获取对应的实现类
- 线程不安全
多线程情况下使用ServiceLoader加载和遍历是不安全的
- 错误难定位
加载不到实现类时抛出并不是真正原因的异常,很难定位问题
五
SPI应用场景
SPI有很多应用场景,最典型的就是数据库驱动,对于jdbc来说,官方只定义了规范,具体的实现由各个厂商自己负责,然后java通过DriverManager将驱动加载进来供程序使用。
DriverManager中一段静态代码块:
/**
* Load the initial JDBC drivers by checking the System property
* jdbc.properties and then use the {@code ServiceLoader} mechanism
*/
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}从注释中可以看出大致意思就是利用ServiceLoader加载数据库驱动供使用。代码块里边调用了私有静态方法loadInitialDrivers:
private static void loadInitialDrivers() {
String drivers;
try {
drivers = AccessController.doPrivileged(new PrivilegedAction() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
} catch (Exception ex) {
drivers = null;
}
// If the driver is packaged as a Service Provider, load it.
// Get all the drivers through the classloader
// exposed as a java.sql.Driver.class service.
// ServiceLoader.load() replaces the sun.misc.Providers()
AccessController.doPrivileged(new PrivilegedAction() {
public Void run() {
//通过ServiceLoader加载驱动类
ServiceLoader loadedDrivers = ServiceLoader.load(Driver.class);
Iterator driversIterator = loadedDrivers.iterator();
/* Load these drivers, so that they can be instantiated.
* It may be the case that the driver class may not be there
* i.e. there may be a packaged driver with the service class
* as implementation of java.sql.Driver but the actual class
* may be missing. In that case a java.util.ServiceConfigurationError
* will be thrown at runtime by the VM trying to locate
* and load the service.
*
* Adding a try catch block to catch those runtime errors
* if driver not available in classpath but it's
* packaged as service and that service is there in classpath.
*/
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
println("DriverManager.initialize: jdbc.drivers = " + drivers);
if (drivers == null || drivers.equals("")) {
return;
}
String[] driversList = drivers.split(":");
println("number of Drivers:" + driversList.length);
for (String aDriver : driversList) {
try {
println("DriverManager.Initialize: loading " + aDriver);
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
}首先从获取属性jdbc.drivers,然后通过ServiceLoader加载驱动类并实例化,如果jdbc.drivers是空值直接返回,否则将其用冒号分割成数组并逐个加载初始化。整个过程做了两件事:
- 将java.sql.Driver的所有实现类加载并初始化
- 将系统指定的驱动jdbc.drivers加载初始化
总结
本篇文章讲述了SPI的概念、API和SPI的区别和联系,SPI的使用方式与原理和源码分析,以及SPI的常用应用场景,也分析了其优缺点,我们可以发现其本质上就是一个能力扩展方式,将接口定义和实现解耦,但是实现方式并不完美,最难以接受的就是无法按需加载和按需获取,当然这些Dubbo的SPI机制提供了更好的实现,在弥补了上述缺陷的基础上有添加了其他比较强大的功能,比如自适应、默认实现和注入等等。可以对比java内置SPI和Dubbo的SPI机制来加深对SPI的理解。
参考
https://docs.oracle.com/javase/7/docs/api/java/util/ServiceLoader.html
https://dubbo.apache.org/zh-cn/docs/source_code_guide/dubbo-spi.html
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.dandroid.cn/17162,转载请注明出处。



评论0